Posted January 27, 2026 by Kelly Tuttle, Manuscript Data Curation Fellow
Hi everyone. My name is Kelly Tuttle, and I’m the Manuscript Data Curation Fellow for the next two years. My background is in Arabic, and my interests are in Islamicate manuscripts. I am delighted to join DS since I have long wanted there to be a union catalog of manuscripts for North America since we have so many collections, many of them still incompletely cataloged, with little way to run data queries or even search in those collections together.
As a way to learn more about the DS Catalog in general and the Islamicate manuscripts that it contains so far, I decided to run a few SPARQL queries. Since there are so many example queries already provided, I ran some of those that interest me first to see what kinds of items are in the catalog right now. This is easy to do, you simply select a query and tell it to run (hit the arrow button). If you haven’t yet done this, you should try it; it’s worth a few minutes. You can then take those example queries and modify them or build on them and look for areas of the collections that really interest you.
If you are feeling intimidated by this prospect, you can start with very simple substitution queries. For example, I first modified an example query provided by DS. The example was for finding items with the standardized title “Book of Hours”. I simply changed one line in the query to find copies of the Qur’an instead by swapping in the identification number for the standardized title “Qur’an” (Q3697) in place of the Book of Hours (Q795). If you are wondering how to find this number, you can go to the catalog and search for the title and copy the number that accompanies it. I left the rest of the query the same because I wanted the same information about each manuscript that the query was already seeking.
?titleStatement pq:P11 wd:Q795 . → ?titleStatement pq:P11 wd:Q3697 .
The query gave me a nice list of 156 copies with the record URL, title, holding institution, date and place. I then exported that as a csv so I could edit it by hand. I knew some of the UPenn data had not yet been added to DS, but would be soon, so I manually added to my spreadsheet some 20 manuscript copies of the Qur’an that I knew about from a previous project.
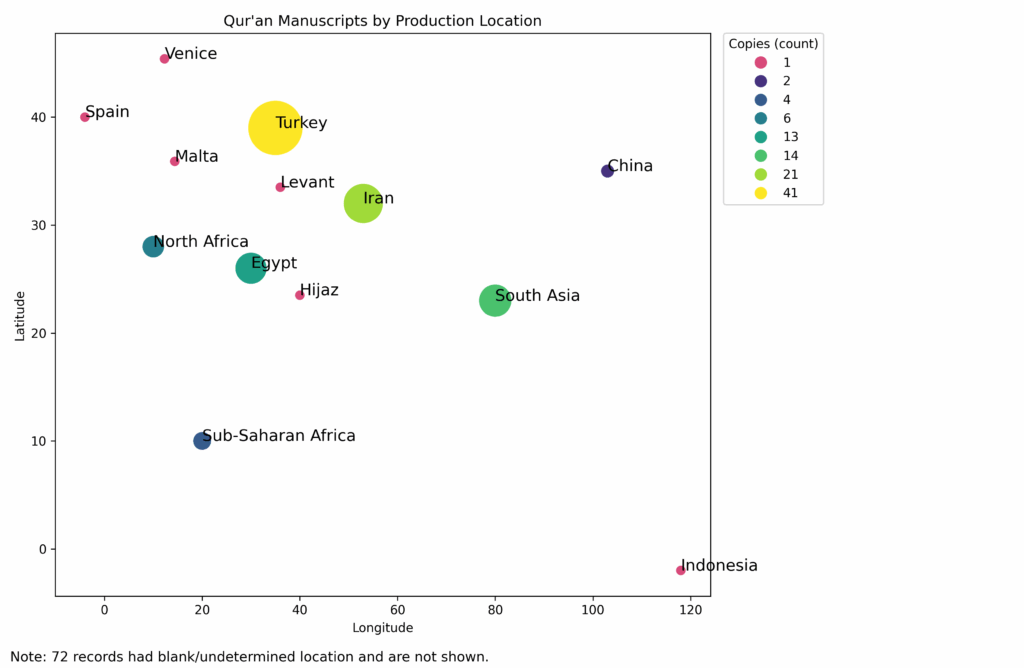
After I verified that the spreadsheet had all the information I wanted, I put it into ChatGPT (since that was the AI tool I had to hand) because I wanted to see if it could make me a visualization of the data. After some iterative prompting, I got the map-like visualization below with a note that 72 of the manuscripts had no place listed and were therefore not mapped. For me, this map reflects what I would expect to find in many North American collections. Most copies are from Turkey, followed by what is now Iran, then South Asia or North Africa/Egypt and some outlier examples from other places. Of course, if we were to look at specific institutions’ collections, we may find different results because of how the collection was built or the interests of donors. As we continue to receive datasets to add to DS, we can rerun these queries periodically and begin refining our understanding of what is held in North American collections.
After that initial query, I decided to try something more complex. I am interested in scribes, so I wanted to look at manuscripts in Arabic, Persian, or Ottoman Turkish with named scribes. I first ran another substitution query to find just the manuscripts that had Arabic, Persian and Ottoman Turkish. As in the first query, I used the DS-provided example for Japanese, Korean, and Chinese and swapped in the appropriate language identification numbers for the languages I wanted.
VALUES ?language { wd:Q12711 wd:Q12712 wd:Q12715 } → VALUES ?language { wd:Q118 wd:Q120 wd:Q3104 }
Note that you can verify you got the correct language code by hovering over the code number once it is in the query. If it shows up as something other than the language you want, then you’ve grabbed the wrong number. Again, you can look these up in the catalog to find the number. This query got me the manuscripts in the correct languages (6,126).
Then, because I’m not an expert in writing these types of queries, I turned to ChatGPT and had it help me construct the parts for the rest of the longer query in a piecemeal fashion, checking the results after every request modification. Not all of the queries were immediately successful. It took a bit of back and forth to get the query built out the way I wanted it and so that it would run correctly in the DS SPARQL endpoint.
The first step was to modify the language query to include only those manuscripts that had a date (either supplied by a cataloguer or in the manuscript). Then, I added to that query (language + date) the request for only manuscripts with named scribes. The scribe query is in the example folder already, so I gave that to ChatGPT as an example to incorporate into the query. Finally, I added an option for listing the place of production, if available. That final query (for language, date, scribe’s name and optional place of production) listed 512 manuscripts of which 361 had no place listed. I exported the list, cleaned it up manually, and checked it over for accuracy. Then, I put the file into ChatGPT to ask for a visualization of the data. After some discussion and revisions, the heatmap below was produced. Again, I checked it over to see if it seemed to match with the dataset that had been given to the AI.
From this fairly small sample set (only 151 manuscripts), we can see that more named scribes appear in Iran, South Asia and Turkey than in other places and that they appear a bit later, 15th century and after. Egypt, the Levant and Iraq have some earlier names. This makes sense if we think about the spread of Islam, Islamicate manuscript production in general, and that the collections in DS so far tend to have more later manuscripts with not as many early examples. North Africa and Spain are not represented very well in these results, which is an effect of which collections are in the DS Catalog.
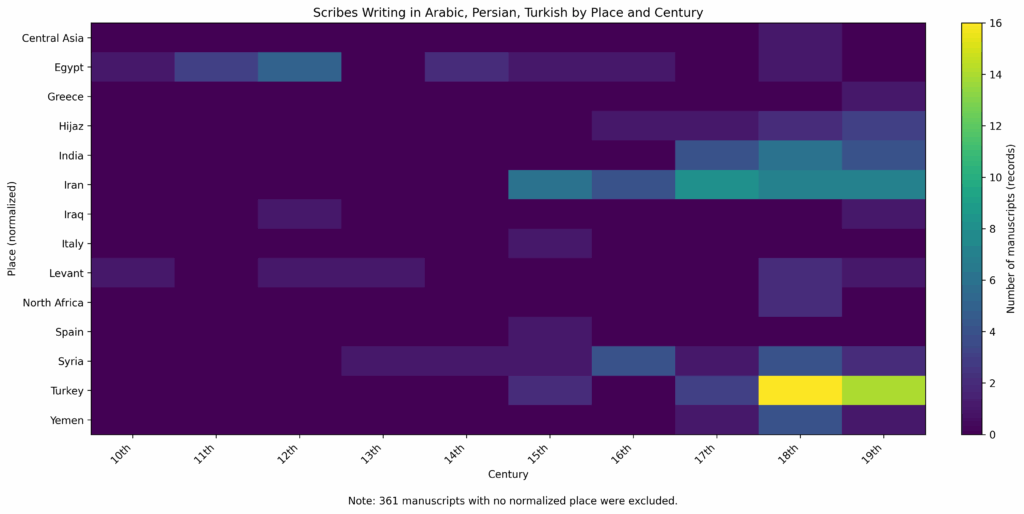
We could further break this down by language, if we wanted and make similar maps for each one. I was also curious to note that only about 10% of the manuscripts with dates also had scribes’ names. I’m not sure how that percentage would change were we to break this down in a little more detail regarding place. I have the data, however, so maybe I’ll look into that.
These are all very preliminary results. However, as more data comes into DS, we will start to have a bigger and more complex catalog on which to run such queries. I will be rerunning these queries once we get more of the Islamicate manuscript collection data added to DS. We are currently working on adding more of Princeton’s collection, which will likely change the results and continue to inform our understanding of Islamicate manuscripts in North America.
As always, if you are interested in joining DS or in having help cataloging what is in your collection, please get in touch. The more data the better!