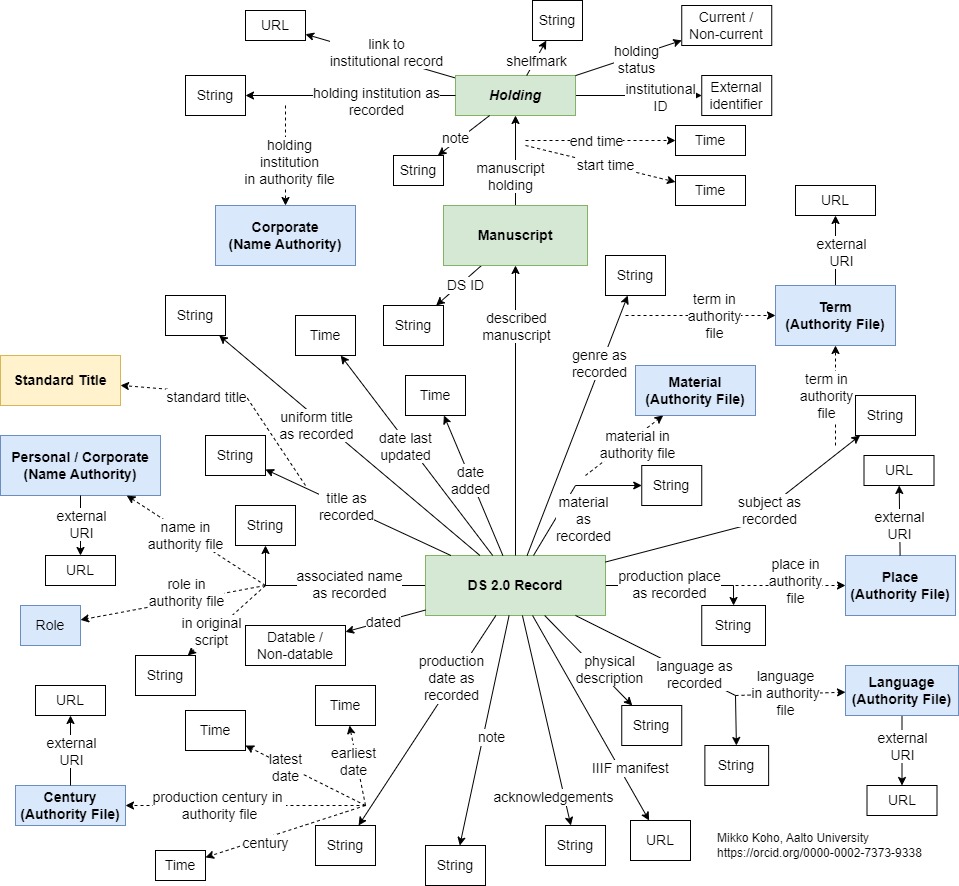
The data model allows representation of three main entities (green rectangles): Manuscripts, Records, and Holdings. Manuscripts are physical manuscript objects as they exist in the real world. Records are metadata descriptions about a Manuscript, based on contributed institutional data like library and museum catalog records or archival descriptions. Holding are metadata descriptions of holding information about a Manuscript, both current and non-current.
Those three types of entities form the backbone of the data model, in which Records describe a physical Manuscript object, which is in turn described as being currently or previously held for a period of time by a particular institution. The model is noteworthy in that it separates representation of the physical object from its catalog record / metadata description. This means that DS conceptualizes the institutional metadata record as a cataloger’s observation of a manuscript object which can be revised or overwritten as cataloging practices and scholarship warrant, while the physical object retains a unique and persistent ID (known as a DS ID) despite descriptive and holdings changes.
The data model also allows standardization and enrichment of metadata by linking data values recorded in catalog records to Linked Open Data authorities and controlled vocabularies (yellow and blue rectangles). This allows us to retain institutional data as it appears in metadata records while at the same time supporting faceted browsing and searching as well as contextual exploration of the data through semantic technologies.
For information about which vocabularies are used for enrichment, click here.
To view our Authority Management and Data Enrichment Plan, click here.
To view metadata mapping decisions between the DS data model / metadata elements and other metadata schemas and encoding standards, click here.
To learn more about querying linked data, click here.
A JSON version of our data model (Wikibase items and properties) can be found here.