Posted February 18, 2025 by L.P. Coladangelo, DS Catalog Project and Data Manager
Gathering metadata records from multiple institutions using multiple standards and formats can be a daunting task. Collecting and organizing the data alone requires a lot of work, but what about making all of that data (re)usable in one place? The DS Catalog is intended to be a “one-stop shop” (i.e., union catalog) when it comes to initial discovery of premodern manuscript objects held in many different places. The DS Catalog is also meant to be a database for computational and digital humanities research, making manuscript metadata machine processable. These goal are complicated by the fact that the available data weren’t originally structured to play well together.
The DS Catalog helps meet these goals by making institutional metadata more powerful and more reusable through semantic enrichment. Semantic enrichment is a process for adding contextual information and meaningful relationships to existing data, which can be accomplished through a number of different strategies. DS uses two such strategies, data reconciliation and semantic annotation, to enhance member metadata. Metadata values that occur in member records are matched to external Linked Open Data authorities and vocabularies through a semi-automated reconciliation process. Reconciled data is then used to semantically annotate metadata when published in our DS Wikibase database.
Reconciliation begins with extraction of all of the metadata values of a certain type: all the names, places, subjects, languages, etc. that are recorded in the metadata records used to describe member-owned manuscript items. Those lists of metadata values are then reconciled to equivalent (or near-equivalent) entities in other vocabularies and authorities in an effort to better standardize the data. For instance, all versions of a place name (including variations and different spellings, and even misspellings) can be grouped together by being reconciled to a single representation of that place in the Getty Thesaurus of Geographic Names. These reconciliations are then maintained in a series of metadata repositories that are automatically referenced when records are uploaded.
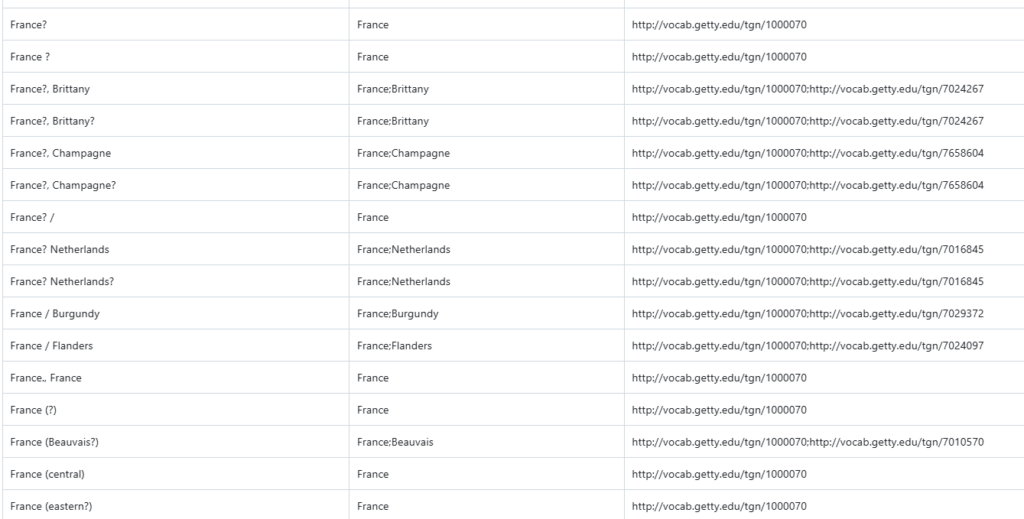
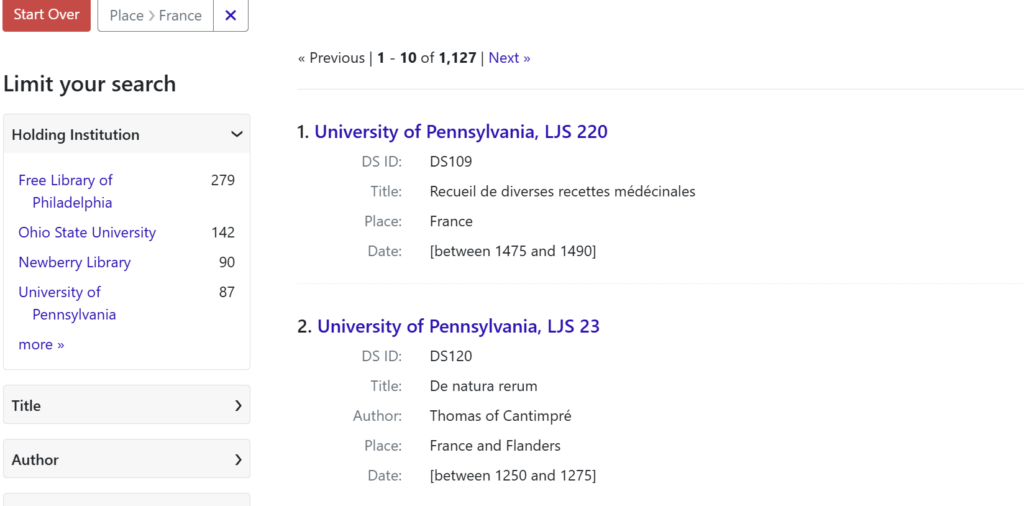
Reconciled data is then used to qualify, or annotate, all of the different values provided in the source metadata to allow harmonized and unified browsing and searching. Rather than relying on keyword searching or fuzzy matching, the DS Catalog can aggregate records on the basis of the annotated data, finding all records with data values which have been properly reconciled. Using a structured relationship, the annotated value modifies the existing metadata in our DS Wikibase database using an internal authority record built on documentation based on our data reconciliation workflows.

The results of these semantic annotations are visible not just when using our front-end search interface, but also through the complex query service supported at the back-end of the database:
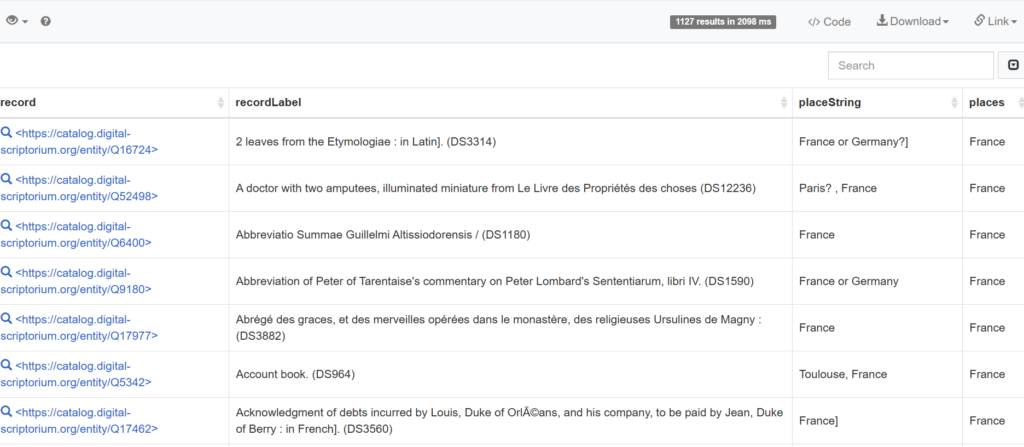
The use of these strategies results in not just more reliable search and retrieval, but the ability to connect to other datasets that use similar Linked Open Data principles and technologies as well as facilitating the use of machine processing for computational and other large-scale data research. This makes member metadata more reusable and more powerful by supporting interoperability and the linking of contextual information found in other datasets and sources.